Optimizing Contrastive Learning Models via Preference Optimization
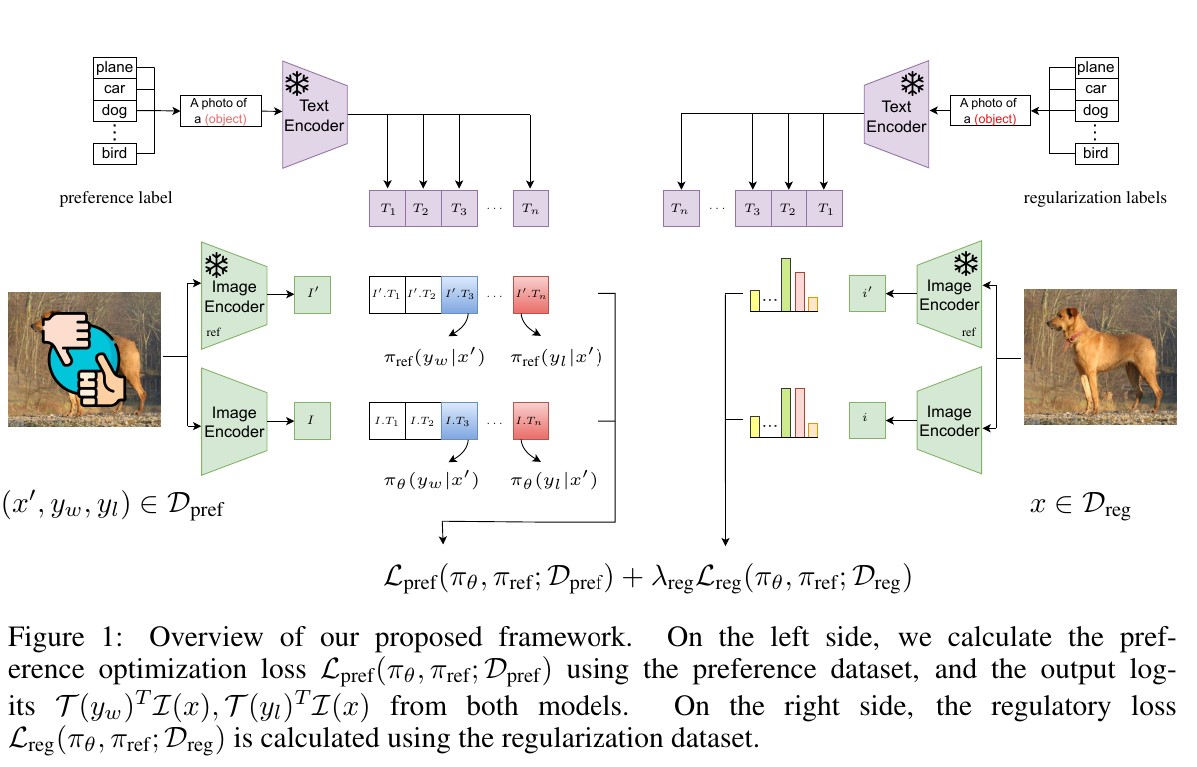
Fine-tuning contrastive models like CLIP using human preference data, improving alignment and robustness against dataset biases and backdoor attacks.
Authors: Amirabbas Afzali*, Borna Khodabandeh*, Ali Rasekh, Mahyar JafariNodeh, Sepehr Kazemi Ranjbar, Simon Gottschalk (*equal contribution)
Venue: ICLR 2025
Contrastive models like CLIP learn representations by aligning image-text pairs, but the resulting representations can reflect dataset biases and are vulnerable to backdoor attacks. Policy optimization methods from RLHF offer a principled way to fine-tune these models using human preference signals.
This paper introduces a preference optimization framework for contrastive models. By treating the contrastive model as a policy and constructing preference pairs from human annotations, we apply direct preference optimization to shift the representation space toward human-aligned features. The result is a model that is more robust to dataset biases and backdoor attacks while retaining strong zero-shot performance.
This work was conducted at the L3S Research Center.